
Business Intelligence API in 2026: The Three Archetypes
Search "Business Intelligence API" today and you find three different products wearing the same name. One returns dashboards over HTTP. One returns firmographic records keyed on a company ID. One returns structured events an AI agent can act on in milliseconds. They are not substitutes, and the cost of treating them as substitutes shows up later, in production.
This guide maps all three archetypes, shows where each fits, and gives you the evaluation checklist that applies across the category. The audience is anyone building decision systems that need company-level intelligence at production speed: data engineers, AI/ML teams, deal teams, compliance teams, and the analysts and traders downstream of them.
What a Business Intelligence API actually is in 2026
A Business Intelligence API is an HTTP interface that returns business-relevant data, insights, or signals in a structured, machine-readable format. The term covers three distinct archetypes in 2026: reporting APIs that expose dashboards from BI platforms, reference data APIs that return firmographic and financial records, and signal APIs that stream real-time events for AI agents and decision systems.
That single definition is doing a lot of work. A data engineer at a SaaS company hears "BI API" and thinks Power BI REST. A platform engineer at a fintech hears it and thinks D&B Direct. A founder building an investing agent hears it and thinks something else entirely: a structured stream of company events with materiality scores attached. All three are correct. None of them are the same product.
How the term fractured between 2018 and 2026
For most of the 2010s, "Business Intelligence API" had one meaning: a programmatic way to query a BI platform. Tableau, Microsoft Power BI, Qlik, Looker, MicroStrategy, and the rest of the enterprise stack published REST APIs so developers could embed dashboards, automate report generation, and push data into governed semantic models. Gartner's Magic Quadrant for Analytics and Business Intelligence Platforms still treats API and SDK support as a core evaluation axis in the 2025 edition, with Looker singled out for its "API-first design for composable analytics" (Gartner Magic Quadrant for Analytics and Business Intelligence Platforms, 2025).
The second meaning came from the data-broker world. Dun & Bradstreet, ZoomInfo, Crunchbase, BizAPI, SavvyIQ, and a long list of vertical firmographic vendors started calling their endpoints "business intelligence APIs." These products do not return dashboards. They return records keyed on a company identifier: NAICS codes, employee counts, addresses, executives, parent-subsidiary trees. SavvyIQ now claims coverage of 265M verified global entities, and D&B's graph anchors thousands of credit, KYC, and supplier-risk workflows globally.
The third meaning is post-2022 and accelerating fast. As AI agents moved from demos to production, the bottleneck stopped being model capability and started being data freshness. Gartner now forecasts that half of business decisions will be augmented or automated by AI agents over the next several years, against a global BI market projected at $27.5 billion by 2027 at a compound annual growth rate of 8.7%. Neither of those numbers gets realized on weekly batch loads. Agents need a third kind of API: one that streams structured business events, scored for materiality, ready to act on. That is the signal layer.
Archetype 1: the Reporting API
Reporting APIs let you query, embed, or orchestrate a BI platform programmatically. Power BI REST, Tableau REST, Looker API, MicroStrategy REST, and Databricks Genie API all sit here. The unit of work is a dataset, a dashboard, an alert, or a natural-language question routed through a semantic layer.
What they are good at: distributing governed insight inside an application. If you run a CRM and want a Looker tile to render inside the deal record, this is the API you call. If you operate a customer portal and want each customer to see a sliced version of their own usage, this is the API you call. Databricks' AI/BI Genie now exposes its conversational interface programmatically, so an agent inside Slack can ask a business question against governed data and return an answer with confidence scores.
What they are not good at: telling you about the outside world. A Power BI dashboard knows what you put in it. It does not know that your second-largest customer's parent just got named in an SEC investigation. Reporting APIs are inward-facing by design. If your stack already runs on one of these platforms and you want to embed analytics into a workflow, evaluate them. If your problem is external intelligence, look at archetype two or three.
Archetype 2: the Reference Data API
Reference data APIs return structured records about companies, keyed on an identifier the caller supplies. D&B Direct, ZoomInfo, Crunchbase Enterprise, BizAPI, SavvyIQ, and a long tail of vertical providers live here. You give the API a company name, a domain, a DUNS number, an SIQ ID. It gives you back a profile.
What they are good at: filling out a record. Enrichment at point of sale, KYC onboarding, credit decisioning, lead routing, NAICS-based segmentation, supply-chain risk scoring on a known counterparty. SavvyIQ's catalog of 265 million entities and D&B's seven-decade-old graph are designed for this exact pattern: deterministic lookup, structured response, predictable schema. BizAPI similarly markets coverage on over 220 million US and international business locations, with NAICS classification and firmographic appends.
What they are not good at: telling you something is happening right now. A reference data API gives you the state of a company at the time of the most recent crawl. The freshest firmographic providers refresh on rolling cycles measured in days or weeks; some financial fields update monthly. For a credit underwriting workflow, that is fine. For an agent that needs to react to a layoff announcement at 9:32 AM, it is not.
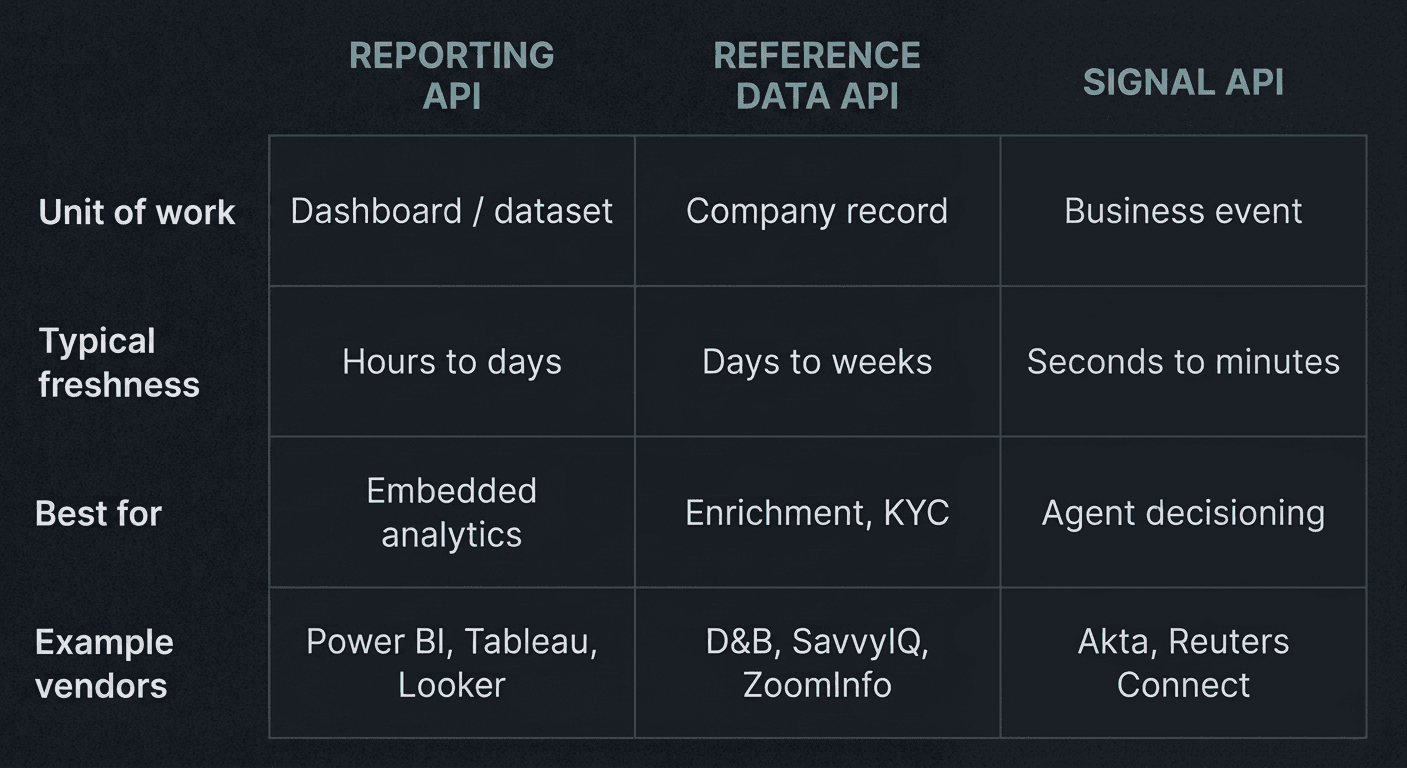
Archetype 3: the Signal API
Signal APIs deliver structured business events, not records. The event is the unit of work: a press release, an SEC filing, a court docket, a layoff, an executive departure, a regulatory action, a partnership, a product launch. Each event arrives with metadata an agent can act on, including timestamps, entity links, sentiment, and a materiality score.
This archetype is newer than the other two because it is built for a consumer that did not exist at scale until 2023: the autonomous agent. Classic news API products (NewsAPI, GDELT, the major newswires' enterprise feeds) were built for human analysts and BI dashboards. They return articles. An article is not a decision. A signal is.
Akta, the news API built for agent workflows that Wokelo AI ships, sits in this archetype. So do a handful of competitors building for the same shift. The category-defining capabilities are: entity resolution across parent companies, subsidiaries, and trading names; deduplication across syndicated wires; materiality scoring; sentiment scoring at the event level; and clean schema stability over time. Akta's entity-resolved company graph covers 20M+ parent companies, subsidiaries, and trading names (Akta, 2026), which matters more than raw coverage volume.
When you need this: any workflow where a decision depends on something that just happened. Earnings-day trading agents, M&A target monitoring, supplier risk surveillance, competitive intelligence dashboards that need to be alive, agent-based sales triggers, compliance screening that runs in real time. If the answer to "how stale can the data be?" is "measured in minutes," you are in archetype three.
The same shift is visible in the broader infrastructure conversation. A recent analysis of production agent stacks argued that sub-second to low-single-digit second freshness is the target for most production agent use cases; anything beyond ten seconds introduces meaningful decision error. That standard rules out the first two archetypes for live decisioning.
How to choose: a decision matrix
Match the archetype to the question your system actually needs answered.
If the question is "what do my internal numbers look like right now," you need a Reporting API. Power BI, Tableau, Looker, Databricks Genie. Evaluate on embedding, governance, and semantic-layer support.
If the question is "tell me everything you know about this specific company," you need a Reference Data API. D&B, SavvyIQ, ZoomInfo, BizAPI. Evaluate on entity coverage, identifier resolution, refresh cadence, and the accuracy of the static fields you depend on.
If the question is "tell me what just happened that affects this company," you need a Signal API. Akta, Reuters Connect (for licensed wire), specialized regulatory feeds. Evaluate on entity resolution, latency, materiality scoring, sentiment, and schema stability.
Most production systems combine at least two. A BD agent might call a reference API to enrich an account at first touch, then subscribe to a signal API for ongoing events. A trading desk might pull internal positions from a reporting API and overlay external signals from an event API. Treat the three as complementary, not interchangeable.
What to evaluate inside any Business Intelligence API
The category is fragmented but the buyer's checklist is not. Whichever archetype you are shopping in, the following criteria separate production-grade APIs from those that look fine in a demo and break in week two.
Entity resolution. Can the API tell that "Apple," "Apple Inc.," "AAPL," and "Apple Computer Inc." are the same legal entity, or that Instagram's news rolls up to Meta? This is the single biggest predictor of downstream agent quality. Coverage volume without resolution is noise. For any workflow involving more than a few hundred companies, this is the first capability to test.
Schema stability. Does the response shape change without warning? A BI API that adds breaking changes to its JSON schema every quarter will burn three engineering days every time. Read the changelog before the trial, not after.
Freshness and latency. Reference APIs refresh on rolling cycles measured in days; signal APIs need to be measured in seconds to low minutes. Ask for the median and 99th percentile latency between the source event and the API response. If the vendor cannot answer, the answer is "too long."
Materiality or scoring layer. A raw stream of company events is not directly useful. An agent needs to know which events deserve a callback to the LLM and which are noise. Look for a built-in scoring field, not a post-processing exercise you have to build yourself.
Coverage. For reference APIs, ask how many entities and how the long tail is sourced. For signal APIs, ask how many sources, how often they sync, and what languages are covered. Coverage claims without a clear source-tier breakdown are marketing.
Rate limits and pricing model. Per-call pricing on a high-volume agent system is a trap. Look for predictable monthly tiers and burst headroom. Per-document pricing is fine for one-off enrichment; ruinous for streaming.
SDKs and auth. Production teams ship faster on APIs that publish Python, JavaScript, and cURL examples in their docs, support OAuth or API-key auth without surprises, and expose webhooks for push patterns. Polling-only APIs are a 2018 architecture.
A signal API call, end to end
Here is what a signal-archetype call looks like in practice. The request is a single GET; the response is structured for an agent to route on.
python
Three things are worth noting about that response shape. First, every article is already tagged with an entity-resolved company identity, so "nvidia" and "NVIDIA Corp." both land on the same record. Second, newsworthiness_impact is the materiality score; it lets the agent filter out the routine signal and spend LLM tokens only on events that warrant reasoning. Third, the loop is the entire agent integration. No NLP layer, no dedup script, no entity disambiguation pass. That work happened upstream, which is the point of the archetype. The full schema and additional endpoints are documented in Akta's API documentation.

Where this is heading
The category is consolidating around three patterns. None of them are speculative; they are already in production at the more advanced shops.
First, agent-native protocols. Model Context Protocol (MCP) and similar agent-to-tool interfaces are starting to wrap traditional REST endpoints, so the same BI API will be callable as both an HTTP service and a tool an agent loads at runtime. Connecty AI now supports interaction via API/MCP for agentic workflows, and Databricks Genie exposes a comparable programmatic surface. The major reference data providers will follow.
Second, the merger of reference and signal data. A modern BI API stack will deliver both static profile and the live event stream from the same vendor, joined by the same entity graph. Customers do not want to maintain identity reconciliation across two vendors; whoever owns the entity layer wins the integration.
Third, materiality as the new ranking layer. The job of ranking news for human readers was solved twenty years ago. The job of ranking events for AI agents is being solved right now. Whichever provider gets materiality scoring closest to ground truth, calibrated against actual downstream decisions, becomes the default. Search rankers won the 2000s; recommendation rankers won the 2010s; materiality rankers are the open competition of the late 2020s.
The shorthand is this: pick the archetype that matches the question your system needs to answer, then evaluate it on entity resolution first and everything else second. The vendors who get that order right end up in production. The ones who do not end up in the architecture-review postmortem.
FAQ
What is a Business Intelligence API?
A Business Intelligence API is an HTTP interface that returns business data, insights, or events in a structured, machine-readable format. In 2026, the term covers three archetypes: reporting APIs that expose BI platform data (Power BI, Tableau, Looker), reference data APIs that return firmographic records (D&B, SavvyIQ), and signal APIs that stream real-time events for AI agents and decision systems (Akta, specialized regulatory feeds).
How is a Business Intelligence API different from a BI tool?
A BI tool, such as Tableau or Power BI, is a platform humans use to build dashboards. A BI API is the programmatic interface a developer or agent calls to either drive that platform or to receive business data directly. The tool is the dashboard; the API is the connection your code uses to read, write, or stream the underlying intelligence.
Can I use a Business Intelligence API with AI agents?
Yes, and increasingly that is the primary use case. Reporting APIs feed agent-built dashboards. Reference APIs enrich entity records inside an agent's context window. Signal APIs trigger agents on real-world events. Gartner now expects roughly half of business decisions to be augmented or automated by AI agents over the next several years (Gartner, 2025); the BI API layer is what makes that operationally possible.
What is the best Business Intelligence API for real-time data?
Real-time use cases favor the signal archetype. Reporting and reference APIs are typically refreshed on schedules measured in hours to weeks, which is incompatible with agent workflows that need to react to events as they occur. Evaluate signal APIs on latency from source event to delivery, on entity resolution coverage, and on the materiality scoring layer that filters noise from action-worthy events.
Do I need entity resolution in a Business Intelligence API?
For any workflow involving more than a few hundred companies, yes. Public companies file under one legal name, get acquired, get renamed, and show up in coverage under three different aliases inside a single quarter. Without entity resolution, downstream agents treat the same company as three different records, miss signals, and double-count exposure. It is the single most under-priced capability in API evaluation.


