
News APIs were built for humans who scan headlines. Agents do not scan. They retrieve, rank, decide, and act in milliseconds, and most of the assumptions baked into the legacy news API stack break the moment a workflow becomes autonomous. If you are evaluating a company news API in 2026, the question is no longer "how many sources do you cover." It is whether the data lands in your agent or model in a shape that does not multiply your engineering cost.
This guide unpacks what a company news API actually needs to do in the agentic era, where the category breaks for AI workflows, how dealmakers and developers each use it, and how to evaluate vendors without falling for coverage theatre.
What a company news API is, and why the definition is shifting
A company news API is a programmatic interface that returns structured news articles about specific companies, indexed by entity rather than keyword. In the AI era, it must also resolve entity aliases and subsidiaries, deduplicate events across publishers, score materiality, and return responses in formats AI agents can consume directly. Coverage is table stakes. Resolution and ranking are the actual product.
The category is splitting into two species. Legacy general-purpose news APIs (NewsAPI.org, GNews, Bing News) return articles matched to keywords. NewsAPI.org and similar pioneers index over 50,000 sources across roughly 50 countries, which sounds large until you discover your "Tesla" query also returns articles about Nikola Tesla, Tesla Roadrunner, and the Tesla section of a Walmart electronics aisle. The newer species, built for AI workflows, treats each article as a structured event about a specific resolved entity. Akta sits in this second category, with a focus on company-level resolution across Wokelo's proprietary database of 20M+ companies that includes parent companies, subsidiaries, and trading names.
The shift matters because the consumer changed. In 2024, automated bot traffic surpassed human traffic on the open web for the first time, and RAG-based agent traffic surged 49% in early 2025. The people calling your news API are increasingly not people.
The four failure modes that break naive company news APIs
Most "we tried a news API and it didn't work" stories trace back to the same four problems. Each one is solvable, but only if the API was designed for it.
The alias problem (entity resolution)
A company files under one name, gets acquired, gets renamed, and shows up in a press release under a third name within the same quarter. Meta is Facebook is Instagram is WhatsApp is Reality Labs. Alphabet is Google is Waymo is DeepMind. A keyword-matched feed treats all of these as separate stories. An agent reasoning about Alphabet's regulatory exposure needs them collapsed into one resolved entity tree.
Entity resolution is the canonical hard problem in data cleaning. The naive comparison of n records requires (n² − n)/2 operations, which forces real systems to rely on blocking and indexing techniques to make the problem tractable. Doing this well at news velocity, across millions of new articles per day, with correct subsidiary linking, is the meaningful technical bar. Skip it and you ship an agent that confidently misroutes signals between unrelated companies.
The duplicate problem (event clustering)
A single acquisition announcement gets covered by 200 outlets within an hour. When a story breaks across 500 outlets simultaneously, naive monitoring pipelines drown in duplicates without event clustering. For a human, this is annoying. For an agent running a downstream LLM call on each article, this is a 200x cost multiplier and a 200x latency multiplier, and the agent still does not know whether the second mention adds new information or just repeats the first.
Event clustering, where many articles about one underlying event collapse into a single canonical record with attached coverage, is the difference between a news API that scales agentically and one that quietly bankrupts your retrieval budget.
The signal problem (materiality scoring)
Not every article is worth acting on. A footnote mention of Tesla in a roundup of "stocks to watch this week" is not the same signal as Tesla announcing a recall, and an underwriting agent should not weight them equally. Yet most company news APIs return both with identical metadata.
Materiality scoring, sometimes called newsworthiness or impact scoring, is the layer that lets a downstream model triage. Without it, every workflow ends up building its own scorer, usually badly. Enterprise customers cite "entity resolution scoring and ability to prioritize markets" as the feature that reduces LLM processing costs when assessing risk. The score is not a marketing label. It is a budget mechanism.
The schema problem (built for agents)
A news API designed for a human dashboard returns a headline, a URL, a snippet, and maybe a date. The agent then has to fetch the URL, render the page, parse the content, classify the company, decide on materiality, and only then act. Each hop is a tool call, a token cost, and a failure surface.
A news API designed for agents returns the full extracted article body, the resolved entity, an event class, a sentiment, a materiality score, a deduplication cluster ID, and a timestamp, all in one JSON response. Modern agent-first API design includes explicit capability discovery, idempotent mutations, and structured error responses that agents can map to recovery actions. The difference between getting a URL and getting structured content is the difference between one LLM call and three.

How different teams actually use a company news API
The "company news API" buyer is not one persona. The use cases sit on a spectrum from "I need a feature in my product" to "I need a signal for a trade." Each shapes what you should look for.
Private equity, venture capital, and investment banking
Deal teams use company news APIs to monitor target lists, surface trigger events (leadership changes, fundraising, regulatory actions), and feed diligence research agents. Partners at private equity firms spend 30-40% of their time on sourcing activities rather than execution, according to Axial. A structured company news feed wired into a CRM lets a sourcing agent rank companies by recent signal density rather than alphabetical chance.
The 2025 cycle made this acute. Private equity and venture capital investments in fintech alone hit $18.54 billion in 2025, up 44% year over year, even as deal volume fell about 34%, which means firms are paying premiums for fewer, more concentrated bets. When the average ticket size goes up, the cost of missing a material news signal on a portfolio company or target goes up with it.
Trading and quant desks
For systematic and discretionary traders, news APIs are the catalyst layer. The agent watches for specific event classes (earnings surprises, FDA actions, antitrust filings) on a resolved entity, scores materiality, and routes to an alerting or execution path. Generic news APIs that lack event classification force the desk to build their own NLP pipeline. The build cost frequently exceeds the API subscription by an order of magnitude.
Competitive intelligence and business development
Account teams need to know when a target account has a new CISO, raised a round, lost a major customer, or opened an office in a new market. After benchmarking six news APIs against real B2B company monitoring workloads, one finding is clear: generic news APIs return noise, and the engineering cost of filtering and entity-matching news articles for B2B relevance dwarfs the API subscription itself. The relevant product is not "news," it is "company events scored for sales-readiness."
Risk and compliance
KYC, sanctions screening, ESG monitoring, and vendor risk teams need adverse media coverage on entities they are exposed to. Here, latency is less important than completeness and provenance. The system has to demonstrate that, if a tier-1 outlet published an adverse story about a vendor on day T, the screening agent surfaced it by day T+1. The API answer must include the publication, the published date, and a stable URL for auditors.
Product teams shipping AI features
A research agent, a sales copilot, a market-intelligence widget, a portfolio monitoring dashboard: every one of these features needs a news layer underneath. Building the pipeline in-house means scraping, dedup, NER, scoring, and source maintenance, which is roughly the work of a dedicated four-person data team. Building in-house demands a dedicated analyst and engineering team to develop, manage, and constantly maintain news data infrastructure, with ongoing scraper repair, NLP pipelines, and metadata tagging. The "make versus buy" math almost always tilts to buy, but only if the API does the work that matters.
What to evaluate when picking a company news API in 2026
Most comparison posts list features. The decision actually turns on a smaller set of criteria that map to whether the API survives contact with an agentic workload.
Entity resolution depth. Ask the vendor: does a query for "Meta" return Facebook, Instagram, WhatsApp, Oculus, and Reality Labs as resolved aliases under one parent? Test edge cases: a private company recently acquired, a public company under a new ticker, a subsidiary with a distinct legal name. If the API requires you to send the exact legal name, it has pushed the resolution problem onto you.
Event clustering and deduplication. Run a query during a known breaking story (an earnings day for a Mag 7 name works well). Count the unique articles returned versus the cluster count. A 200:5 ratio is workable. A 200:200 ratio means you are paying to deduplicate.
Materiality and event classification. Are articles tagged with event types (M&A, leadership change, regulatory action, product launch, earnings, lawsuit, partnership)? Is there a numeric or categorical score for impact? If your agent has to read every snippet to triage, the API has not done its job.
Schema for agents. Does the response include the full extracted article body, not just a snippet? Is the entity ID stable and joinable across queries? Are the field names predictable and documented? Can the API be exposed as an MCP tool or wrapped in a tool-calling spec with reasonable effort?
Latency and freshness. For trading and competitive intelligence workflows, you need sub-minute publication to availability. For diligence research, sub-hour is fine. Ask for the p50 and p99 numbers, not the marketing claim.
Source mix and provenance. Tier-1 outlets, regulatory filings, press releases, regional language coverage, blog and forum sources where appropriate. Each source must come with a stable URL and a publication name for audit trails.
Custom endpoints. For non-trivial use cases, you will want filters that the standard API does not expose: a curated list of 5,000 portfolio companies, a sector taxonomy, a sentiment threshold tied to your risk policy. Vendors that offer custom endpoints save you a glue layer.
Pricing model. Per-call billing punishes high-recall workflows. Subscription with usage tiers and predictable annual pricing makes budgeting tractable. Banks selecting news intelligence vendors specifically flag "predictable annual pricing" as a procurement requirement that drives reusability across departments.
Implementation pattern: wiring a company news API into an AI agent
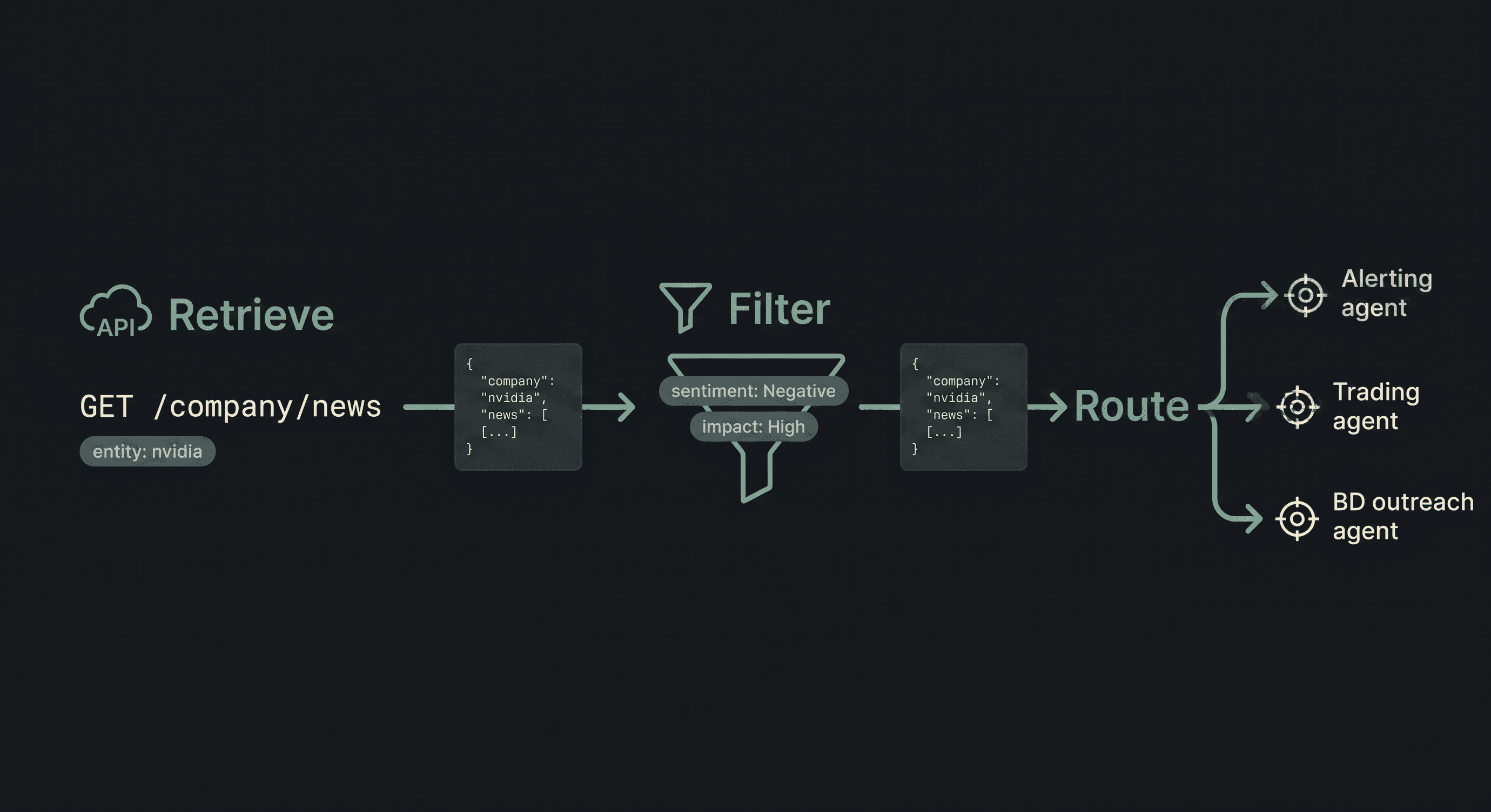
The minimum-viable pattern for an AI agent that acts on company news has three stages: retrieve, filter, route. Here is how that looks against the Akta company news endpoint.
Three notes on the pattern. First, the agent does not see raw headlines until after materiality and sentiment filters apply, which is how you keep token costs sane. Second, the resolved company name is a stable join key, so you can correlate against an internal CRM or portfolio table without fuzzy matching. Third, the event_type field lets a downstream agent decide which playbook to run: a leadership change routes differently from a regulatory action.
For production deployments, add timeout handling, exponential backoff on 429s, a small cache keyed on cluster_id to avoid duplicate downstream work, and a circuit breaker if the score field is missing. None of this is exotic, but the API has to give you those fields for any of it to be possible.
What's next: news APIs as agent tools, not data feeds
The interesting evolution in 2026 is not bigger source counts. It is news APIs exposing themselves natively as agent tools.
The Model Context Protocol (MCP) is the most concrete version of this. Modern agent-first API bundles include an MCP server layer that wraps existing REST endpoints, explicit capability discovery, resumable state primitives, idempotent mutations, and structured executable error responses. A news API exposed as an MCP tool is something an agent in Claude, Cursor, or a custom orchestrator can discover, call, and recover from without bespoke glue code.
A second shift is retrieval contracts. Today, most news APIs treat retrieval as a stateless GET. In agent contexts, you want a contract that says: "Give me everything material on this entity since my last successful poll, ordered by event class priority, deduplicated by cluster, and signal back if a story I retrieved earlier has been retracted." That contract reduces the work the agent has to do and shrinks the hallucination surface. Even with RAG, hallucination rates of 15-30% are observed, or more than one hallucination per 100 output tokens in some settings. Tighter retrieval contracts are one of the better mitigations.
A third shift is the convergence of news, filings, and private data. The same agent that needs a Reuters article on a regulatory action also needs the underlying 8-K, the analyst call transcript, and any private-company context the firm holds. Vendors that treat news as one feed among several, joined on a common entity ID, will outrun pure-news vendors. This is the bet behind Wokelo's approach of unifying a proprietary 20M+ company database, premium datasets, news feeds, and market intel with line-level citations, with Akta as the news-API surface of that stack.
The teams who will win are the ones who treat news as infrastructure for agents, not content for dashboards.
FAQ
What is a company news API?
A company news API is a programmatic interface that returns structured news articles about specific companies, queryable by entity rather than keyword. Modern company news APIs also resolve aliases and subsidiaries, deduplicate events across publishers, score materiality, and return JSON shaped for AI workflows.
How is a company news API different from a general news API?
A general news API matches articles to keywords or topics. A company news API is indexed on resolved entities (the company, its subsidiaries, its trading names) and typically includes enrichment such as event classification, sentiment, and materiality scoring. The difference shows up at scale: a keyword feed for "Meta" returns noise; an entity-resolved feed returns Meta the corporation.
What is entity resolution in a news API?
Entity resolution is the process of identifying that different mentions across articles (legal names, brand names, tickers, former names) refer to the same real-world company. It is a critical task in data integration and quality, especially on the web where the same entity is fragmented across overlapping, redundant records. Without it, agents misattribute signals.
Can I use a company news API for retrieval-augmented generation (RAG)?
Yes, and most modern news APIs are designed for it. The article body, resolved entity, and published date become the retrieved context for an LLM call. Cleaner inputs (deduplicated, scored, entity-resolved) reduce both token cost and hallucination risk. RAG combats hallucinations by grounding the LLM in actual retrieved data rather than parametric knowledge, but the quality of the retrieval layer determines the quality of the answer.
What is materiality scoring in a company news API?
Materiality scoring is a numeric or categorical rating attached to each article that estimates its likely impact on the company. A trivial mention gets a low score; an earnings surprise or regulatory action gets a high one. Materiality scoring lets downstream agents triage and route without reading every snippet.
How much should a company news API cost?
Pricing models split into per-call (often $0.001 to $0.01 per article retrieved), tiered subscriptions ($99 to $5,000+ per month), and enterprise contracts (custom, typically five to seven figures annually for high-volume agentic workloads). For most production AI features, the engineering cost saved by buying a structured API outruns the subscription cost by a wide margin.
What is the best company news API for AI agents?
The right answer depends on use case. For high-recall research workflows, an API with deep historical archive and entity resolution matters most. For trading and competitive intelligence, latency and event classification matter most. For B2B account monitoring, signal pre-scoring matters most. Evaluate against the failure modes covered above (alias, duplicate, signal, schema) rather than against feature checklists.
The next phase of news infrastructure is being designed for an audience that does not read. If your stack still treats news as a feed of headlines, the gap between what your agent can do and what it should do will widen each quarter. Pick the API that resolves the entity, clusters the events, scores the impact, and gets out of your way.


