
How akta.pro decides which company a signal is about — and gets better every time it does.
In short: Private company entity resolution is the task of deciding which real-world company a given name, mention, or signal actually refers to, then attaching it to one stable identity. Public companies have tickers, CIKs, and LEIs to anchor this; private companies have no universal identifier, so the same firm fractures into separate records across sources. akta.pro solves it with a per-company factpack: a structured, living profile across 20M+ companies that is used to validate every incoming signal and is enriched by each one it resolves.
Key takeaways
Names collide across industries and geographies; private companies have no stable handle, which is what makes company entity resolution hard.
The company factpack is both the validator (it decides whether a source is really about a company) and the asset being enriched.
A recall-first funnel: NER → candidate retrieval → ML relevance → LLM confirmation — places each method where it is strongest.
An LLM alone is not enough: it is non-deterministic, biased toward the most famous namesake, and blind to the private long tail.
Resolve identity once and every downstream surface like news entity resolution, alternative data, the company database, agentic workflows, discovery — inherits it.
The problem hidden in a name
Ask a company-intelligence system for "the latest on Apollo" and the decisive step happens before a single result comes back: it has to decide which Apollo you mean. Apollo Global Management, the private-equity firm. Apollo.io, the sales-software company. Apollo Tyres. Apollo Hospitals. Four companies, four industries, one string.
For public companies this is tractable, because tickers, CIKs, and LEIs give you a stable handle. For private companies, most of the economy and almost all of the interesting deal flow, there is no such handle. There is no universal identifier; names collide across industries and geographies; corporate structure such as subsidiaries, trading names, and post-acquisition rebrands is mostly invisible in the source text; and the long tail runs to tens of millions of thinly documented entities.
Resolving identity correctly — the discipline of private company entity resolution — is the precondition for everything downstream: monitoring, enrichment, risk scoring, an agent making a decision.
The company factpack
At the center of the approach is a per-company factpack: a structured, persistent representation of what a company actually is, built across 20M+ companies from a wide source base — company websites, news and press, regulatory filings, job postings and hiring signals, web and app activity, customer reviews, funding and financial data, and licensed firmographics. A field-extraction pass distills each company into a compact, queryable profile.
common_name · legal_name · aliases[] · trading_names[] · former_names[] · domains[] · identifiers (tickers, registry IDs) · product_description · products[] · business_model · industry / sub-sector · firmographics (founding year, HQ, geographies, headcount) · funding (stage, investors, total raised) · key_people[] · competitors[] · customers[] · corporate_structure · tags[]
The factpack is not a static record. It is the working context the system uses to make identity decisions — and, as the next sections show, it is designed to grow each time it is used.
Architecture: build, validate, compound
The system runs in three movements around the factpack.
Build (continuous). Sources are ingested and passed through recall-optimized extraction to produce and maintain each company's factpack.
Validate (real time). A query or a live signal triggers semantic retrieval of candidate sources. Each candidate is checked against the relevant factpack to decide whether it is really about that company, and confirmed results are returned entity-resolved with a confidence score.
Compound. The validated understanding is folded back into the factpack, so its context improves with every signal processed. The factpack is simultaneously the validator and the asset being enriched.

Validating a signal against the factpack
Validation is a funnel that places each method where it is strongest, optimizing for recall first and precision second.
Recall-optimized named-entity recognition (NER) over-extracts every plausible company mention from the retrieved sources. A missed mention is invisible — no one knows it was dropped — and you cannot recover recall you discarded up front.
Candidate retrieval maps each mention to candidate companies in the factpack index using approximate (fuzzy) string matching together with semantic, embedding-based similarity, tolerating spelling, abbreviation, and surface-form variation.
An ML relevance model — a learned classifier that ranks candidates on contextual features — drops the low-probability ones before any expensive reasoning runs.
LLM validation confirms the surviving candidate against the factpack — industry, geography, business model — and returns the entity with a confidence score.
Cheap, broad methods do the early work; the most context-hungry step runs only on a small set of survivors.

A worked example
Take a single company that surfaces five different ways. On LinkedIn it's "Acme, Inc."; in a company database, "Acme Tech"; its web traffic resolves to acme.io; an SEC EDGAR filing lists "ACME Corp."; a reviews platform has it as "ACME CORPORATION." Five surface forms across five sources, one company. A string matcher treats them as five separate records — or worse, fuses some onto the wrong company. An LLM on its own might guess they're related but won't commit to the same answer twice. Validation against the factpack reads each record's context — domain, filings, firmographics, business model — confirms they all describe the same firm, and resolves them to one canonical entity: Acme Inc., akta_co_9d4f1. Five source records in, one resolved entity out.
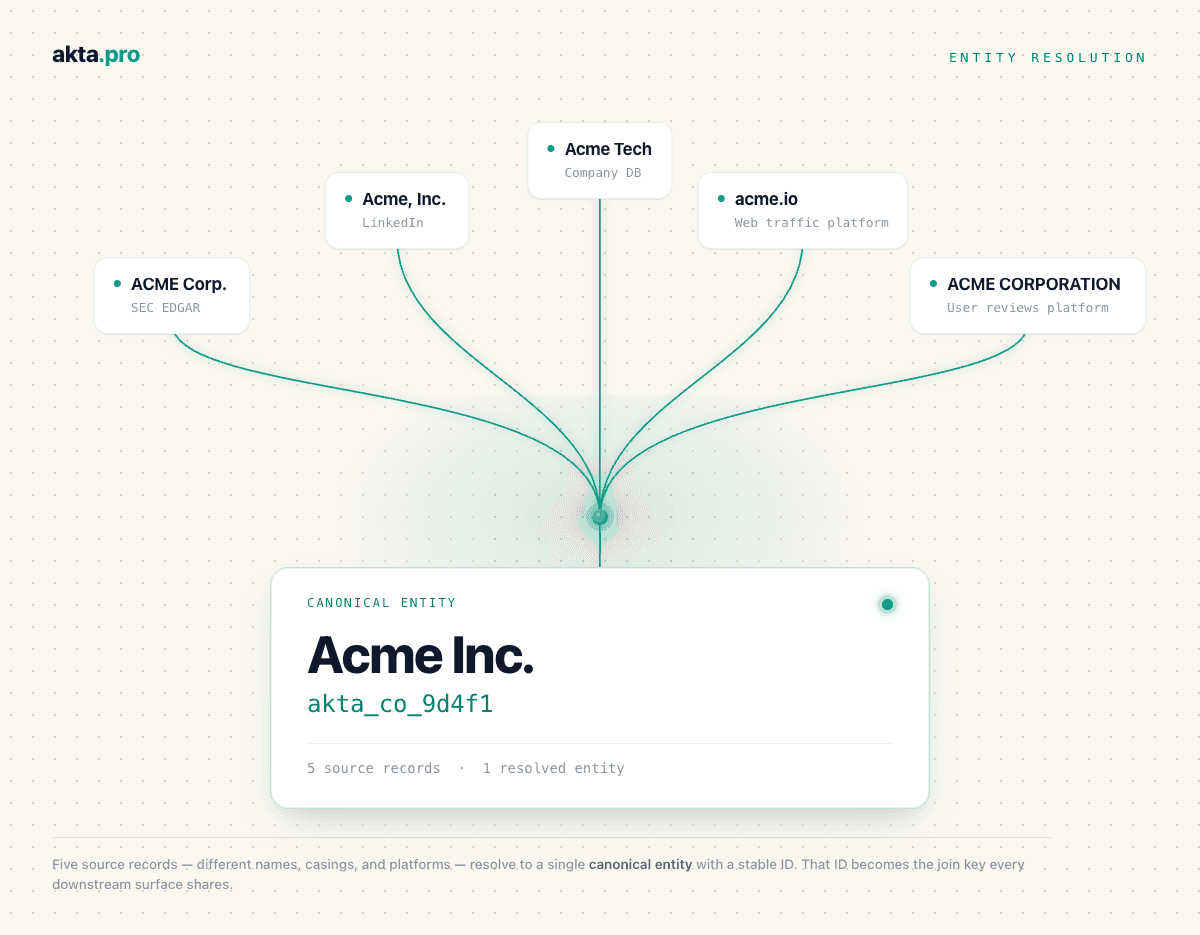
The same machinery separates the three very different companies that trade as "Bolt," and rolls a story that appears only under a brand or trading name up to its correct parent. By the time a caller queries, the resolution is already done:
bash
# every signal returns entity-resolved and classified curl -G "<https://api.akta.pro/api/v1/company/news/>" \\ -H "x-api-key: wk_..." \\ --data-urlencode "company=brex" \\ --data-urlencode "limit=25"
Why an LLM alone is not enough for company entity resolution
A large language model maps text to its own parametric memory, not to a stable, external entity, so it is non-deterministic, biased toward the most famous namesake, blind to the private long tail, and unaware of corporate structure unless that structure is written in the passage. None of this makes LLMs unhelpful — it places them. Their judgment is most valuable as a final confirmation step over a short candidate list with full context, not as the system that scans the world and decides identity on its own.
How this differs from existing approaches
Two categories of product touch this problem today, and each misses a different half of it.
Legacy private-company databases have real coverage of the private long tail, but they reach it largely through human effort: they employ large benches of analysts who manually research, enter, and reconcile company records and decide which entity a mention refers to. That curation is expensive, slow to update, and hard to scale — and it still sits behind restrictive licensing, weak APIs, no usage-based pricing, and nothing designed for an agent to call autonomously.
Newer web-search and news APIs are pleasant to build on and agent-friendly, but optimized for the public web; they are shallow exactly where private markets are deep — the identity layer of subsidiaries, trading names, and namesakes — and tend to return links rather than resolved entities.
The factpack approach is built for the middle that neither serves: agent-native and private-company-specialized, resolved by machine rather than by a back office.
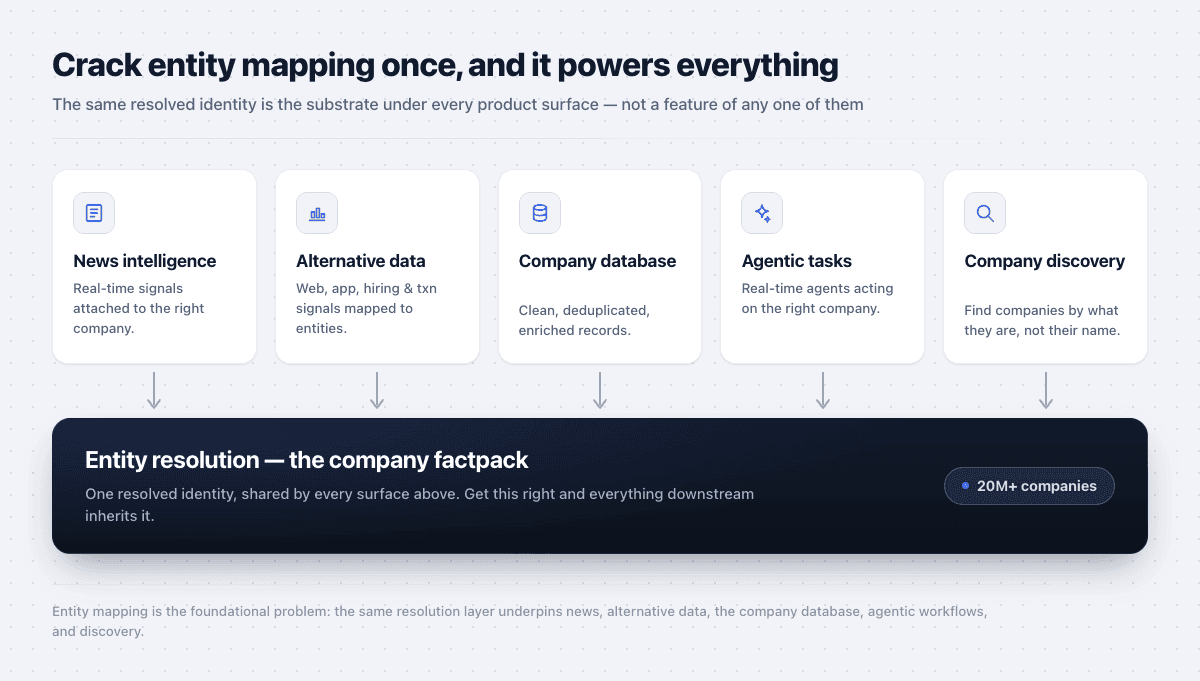
Entity mapping is the foundation
Resolution is not a feature of one product; it is the substrate under all of them. The same resolved identity powers news intelligence, where news entity resolution attaches each signal to the right company; alternative data, with web, app, hiring, and transaction signals mapped to the correct entities; a clean company database of deduplicated, enriched records; real-time agentic tasks, where an agent must act on the right company; and company discovery, finding companies by what they are rather than only by what they are called.
Resolve identity once, and every surface above inherits it — which is why getting entity mapping right is the highest-leverage problem to solve first.
Frequently asked questions
What is private company entity resolution?
Private company entity resolution is the process of deciding which real-world private company a name, mention, or signal refers to, then linking it to a single stable identity. Unlike public companies — which have tickers, CIKs, and LEIs — private companies have no universal identifier, so resolution has to be inferred from context such as industry, geography, business model, and corporate structure.
Why is company entity resolution harder for private companies than public ones?
Public markets have stable handles that never move. Private markets do not: names collide across industries and geographies, subsidiaries and trading names hide a company's true parent, post-acquisition rebrands break the link to prior records, and a long tail of tens of millions of thinly documented firms has almost no public footprint to match against.
How does news entity resolution work?
News entity resolution extracts every plausible company mention from an article, maps each mention to candidate companies, ranks those candidates on context, and confirms the survivor against a structured profile of the company. The result is a news signal attached to one correct entity with a confidence score, instead of an ambiguous name or a list of links.
Can an LLM do entity resolution on its own?
Not reliably. An LLM maps text to its own parametric memory rather than to a stable external entity, so it is non-deterministic, biased toward the most famous namesake, blind to the private long tail, and unaware of corporate structure unless it is stated in the text. It is most valuable as a final confirmation step over a short candidate list — not as the system that decides identity alone.
How is the factpack approach different from legacy databases and web-search APIs?
Legacy private-company databases cover the long tail but rely on slow, expensive manual curation behind restrictive licensing and weak APIs. Web-search and news APIs are agent-friendly but shallow on private-market identity and return links rather than resolved entities. The factpack sits in the middle both miss: agent-native and private-company-specialized, resolved by machine.
Appendix — A validation benchmark you can run
A credible way to document the gap is a controlled error audit that measures, on the same inputs, how often each provider attributes a signal to the wrong company and how often it misses signals that belong to the company.
1. Build a labeled gold set. Assemble 200–500 mentions or company queries, each labeled by analysts with a single ground-truth canonical entity. Stratify into the hard buckets where resolution actually breaks:
Namesake collisions — several real companies sharing a name across industries or geographies.
Subsidiary / trading-name rollups — news under a brand that should map to a parent.
Private long tail — companies with a thin public footprint.
Multilingual / regional — non-English sources, regional namesakes.
Distractors — the famous namesake is present but the intended company is the obscure one; or the term is not a company at all.
2. Pre-register before running anything. Lock the gold set and the labeling rubric before any provider is run, so the test cannot be tuned to a result. Use two annotators plus a tiebreaker and record inter-annotator agreement.
3. Run every provider on identical inputs. Query each provider (akta.pro and the alternatives) through its API with equivalent semantics — "signals for company X" or "resolve this mention" — and capture the returned entity for each item.
4. Score against ground truth.
Metric | What it captures |
|---|---|
Wrong-company rate | Share of returned items attributed to the wrong entity — the headline "how many wrongs." |
Miss rate / recall | Share of true signals about the entity that were missed — catches subsidiary and trading-name gaps. |
Precision / F1 | Overall accuracy, reported per bucket so the gap is visible where it is widest. |
Confidence calibration | Optional: do high-confidence answers actually err less? |
5. Report fairly. Normalize for coverage differences, disclose the methodology and gold set, keep labeling blind to provider, and avoid cherry-picked names. A benchmark that looks rigged is worse than none. Publish the methodology, the aggregate numbers, and a few representative examples; in public materials keep competitors described by category.


